大数据及hadoop概述
大数据的概念
大数据到底是啥?
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。说到底,大数据就是海量的数据,和普通数据区分的标准就是能不能只用单机就能处理的了。大数据领域主要解决海量数据的存储和计算问题。
大数据的处理的数据量级为 TB、PB、EB级别:
1 | 1Byte = 8bit 1T = 1024G 1Y = 1024Z |
大数据的4V特点
Volume(大量):
截至目前,人类生产的所有印刷材料的数据量是 200PB,而历史上全人类总共说过的话的数据量大约是 5EB。当前,典型个人计算机硬盘的容量为 TB 量级,而一些大企业的数据 量已经接近 EB 量级。Velocity(高速):
这是大数据区分于传统数据挖掘的最显著特征。根据 IDC 的“数字宇宙”的报告,预计到 2020 年,全球数据使用量将达到 35.2ZB。在如此海量的数据面前,处理数据的效率就是企业的生命。Variety(多样):
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求。Value(低价值密度):
价值密度的高低与数据总量的大小成反比。如何快速对有价值数据“提纯”成为 目前大数据背景下待解决的难题。
数据部门的一般组织结构
平台组:hadoop、flume、kafka、storm、spark等框架平台的搭建;集群性能的监控;集群性能的调优。数仓组:ETL工程师(数据清洗);Hive工程师(数仓建模及数据分析)。数据挖掘组:算法工程师;推荐系统工程师;用户画像工程师。报表开发组:JavaEE工程师。
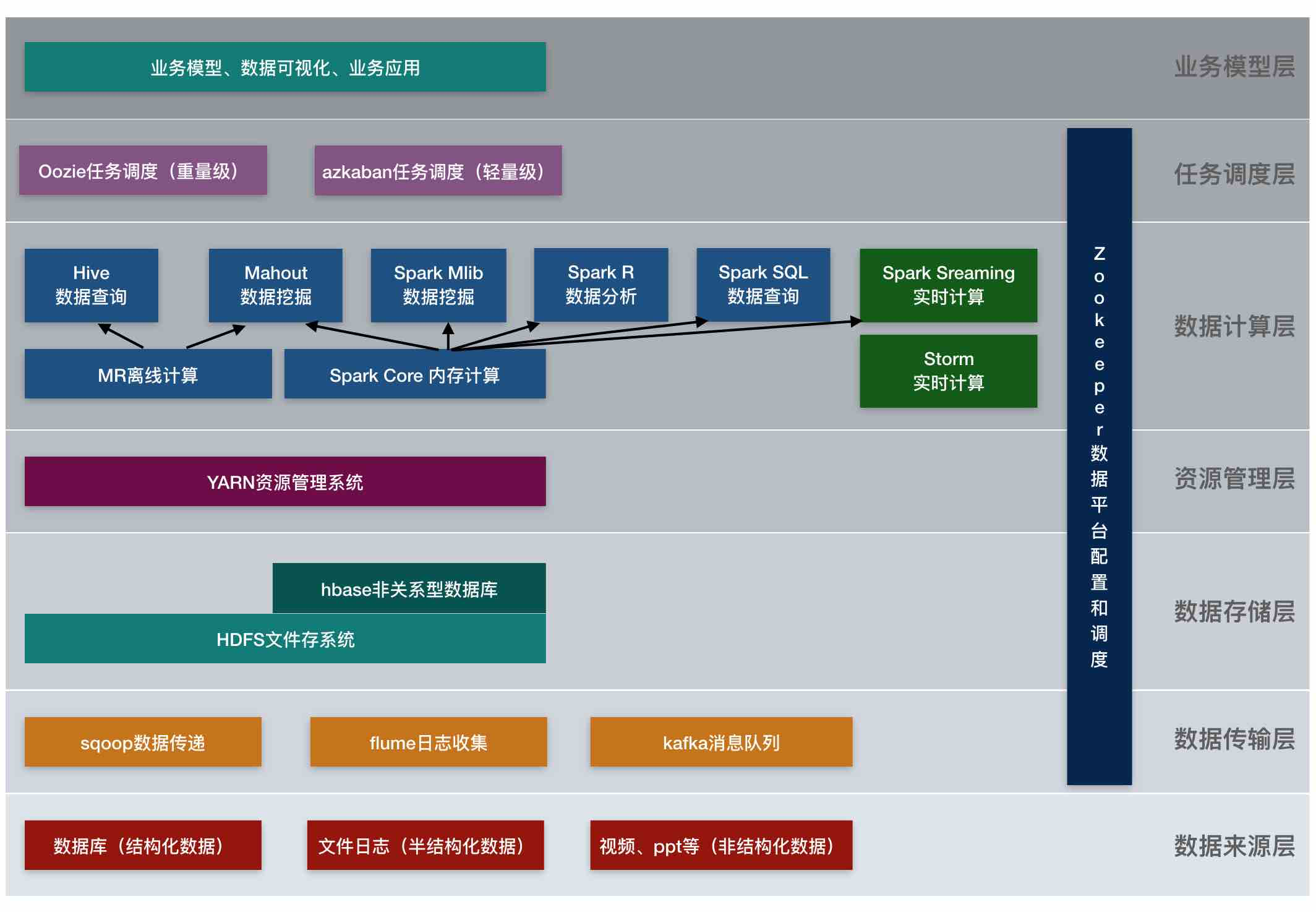
从hadoop框架讨论大数据生态
hadoop是啥?
hadoop现由apache基金会开发维护的分布式系统基础架构,主要解决海量数据的存储和计算问题,从广义上说,hadoop通常是指hadoop生态圈。
hadoop的思想来源于google的三篇划时代论文:
- GFS -> HDFS
- Map-Reduce -> MR
- BigTable -> Hbase
hadoop的组成

- HDFS:hadoop分布式存储系统
namenode(nn):存储文件的元数据,如文件名、文件目录结构、文件属性(生成时间、副本数、权限),以及存储每个文件的块列表和块所在的datanode。secondarynamenode(2nn): 用来监控hdfs状态的辅助后台程序,每隔一段时间获取hdfs元数据的快照;datanode(dn):负责真正存储文件块数据以及数据的校验和;
- YARN:hadoop资源管理和任务调度框架
resourcemanager(rm):处理客户端请求;启动和监控applicationmaster;监控nodemaster;资源分配与调度;nodemanager(nm):单个节点上的资源管理;处理来自resourcemanager和applicationmaster的命令;- applicationmaster:数据切分;为应用程序申请资源并分配给内部任务;任务监控与容错;
- container:对任务运行环境的抽象(封装了CPU|内存等多维资源以及环境变量、启动命令等任务运行相关的信息);
hadoop的优势
高可靠:hadoop默认维护3个数据副本,在出现故障时可以对失败的节点进行重新分布处理;高容错:副本机制保证数据的安全性,失败的任务能够进行重新分配;高扩展:hadoop集群能够方便的扩展数以千计的节点;高性能:mapreduce任务并行工作,任务处理速度倍增;
hdfs的优缺点
优点:
- 高容错性:① 数据自动保存多个副本,② 某个副本丢失之后可以自动恢复
- 适合处理大数据:① 数据规模为TB甚至PB,② 文件规模一般在百万以上
- 低成本:一般可构建在廉价机器集群上
缺点:
- 不适合低延时数据访问,如毫秒级的响应一般是做不到的。
- 无法高效对大量小文件进行存储,因为小文件会占用NN大量内存来存储文件目录和块信息等元数据,并且小文件的寻址时间可能会超过读取时间,这样就违反了HDFS的设计目标。
- 不支持文件的并发写入和文件的随机修改。一个文件只能有一个写,不允许多个线程同时写;仅支持数据的追加写,不支持文件的随机修改。
hadoop三大发型版本
- apache:2005,最原始基础的hadoop版本,对于入门学习最好;
- cloudra:2008,在大型互联网企业中应用较多,兼容性较好,服务收费;
- hortonworks:2011,文档较好。